3D-LLM, NIPS 2023
Abstract
- 3D 공간의 정보 즉, spatial relationships, physics, layout같은 더 많은 정보를 언어모델에게 주입해서 확장해보자
- 3D point cloud와 그것에 대한 feature + LLM query(prompt)를 인풋으로 줌
- 가능한 3D-related tasks : 3D QA, navigation, 3D grounding, captioning, ..
- 크게 세가지의 프롬프트 메커니즘을 통해 3D-language Data를 만들었다
- 학습 방법 : 멀티뷰 이미지들로부터 3D Feature extractor를 통해 3D feature(point cloud)를 얻은 이후 이거를 2D VLM 백본에 넣어주어 3D LLM학습하게 됨
Introduction
- 기존 LLM : chatbot으로써의 역할, communication, commonsense reasoning에 유능함 ⇒ 텍스트 중심
- 요즘의 Multimodal-LLM : image, video를 text와 align하여 2D 공간 비주얼 정보로부터 reasoning가능 (e.g., Flamingo, BLIP-2)
⇒ 3D 공간적 특성을 추론할 수 있는 LLM은 왜 없는가?
Challenges
(1) 데이터의 부족
- 3D Data-Language가 align되어있는 데이터가 없다
- 그래서 본 논문에서 만들었다,
- how? 데이터 만드는 파이프라인에서 ChatGPT와 3가지의 효율적인 프롬프트를 활용해서 약 300K의 3D-language data만들었고 이거를 토대로 다양한 관련 태스크들(3D captioning, dense captioning, 3D QA, 3D task decomposition, 3D grounding, 3D-assisted dialog, navigation)가능
(2) 3D LLM모델에게 언어 텍스트와 align시킬 3D feature를 어떻게 줄 것인지에 대한 모호성
- 3D encoder활용하는 방법
- CLIP에서 2D image끼리 텍스트간 학습했던 것처럼, 3D feature와 language간의 contrastive learning 패러다임 활용하는 방법
- 시간소요, GPU자원, 데이터 양이 많이 필요하다는 점에서 별로임
- 3D feature extractor 활용하는 방법(2D multi-view images로부터) ⇒ 채택
- BLIP-2나 Flamingo같은 2D VLM모델에서는 2D pretrained시킨 CLIP feautre를 활용하기 때문에 이 2D-VLM모델을 백본으로 삼아서 3D feature를 우리모델의 인풋으로 주는거다 (??)
Contribution 정리
- 3D-LLM모델 : 3D Point cloud & language prompt인풋으로 받음 ⇒ 3D-related 다양한 태스크 수행 가능
- 새로운 데이터 수집 파이프라인 제안 : 대규모 3D-language data 300k개 이상으로 구성
- 3D feature extractor 활용해서 렌더링된 2D 멀티뷰 이미지들로부터 3D feature 추출하여 활용 + 2D pretrained VLM을 백본으로 사용 + 3D localization 메커니즘 소개 (3D 공간적 정보를 더 잘 이해하게 함)
- 실험적 얘기 ⇒ ScanNet데이터셋에서 더 BLEU-1 score 소타성능보다 9퍼센트 더 높아짐
3D-language Data Generation
- 최신의 multi-modal data(2D 이미지들과 text pair로 구성된)는 접근성이 좋지만 3D asset에 대해서는 그것들의 “scarcity(희소성)”와 “3D asset에 대한 language data의 부재”로 인해 3D관련 multi-modal data가 많지 않음
기존 존재하는 3D-language 데이터들 : ScanQA, ScanRefer ⇒ 퀄리티와 다양성 측면에서 한계가 있고, 데이터당 하나의 태스크만 가능하다는 점에서 제한적임
- 본 논문에서 새로 만든 데이터 : 다양한 3D관련 데이터 가능한 벤치마크임
- 아래 3개의 효율적인 프롬프트 단계들을 거쳐서 데이터 만듦
- Boxes-Demonstration-instruction prompting
- 3D 공간에서의 방과 물체들에 대한 AABB(Axis-Aligned Bounding Boxes)를 LLM(ChatGPT) 인풋으로 줘서 장면에 대한 semantic, spatial 위치 정보를 제공해줌
- ChatCaptioner based prompting
- ChatGPT한테 해당 이미지에 대한 일련의 question을 만들게끔 프롬프팅하고, BLIP-2 VLM모델에게 이 질문에 대한 응답을 생성시킴.
- 3D-related data를 수집하기 위해, BLIP-2모델에게 multi-view 2D rendered image들을 인풋으로 주고, ChatGPT가 전체 장면에 대한 “glboal 3D 묘사를 형성 및 수집하기 위해 질문 던짐
- Revision based prompting
- 해당 3D data중 한종류를 다른 것으로 바꾸는데 사용 (?)
- Boxes-Demonstration-instruction prompting

- 아래 3개의 효율적인 프롬프트 단계들을 거쳐서 데이터 만듦
3D-LLM Pipeline
Overview
- 2D image-text multimodal data: CLIP처럼 2D image들과 텍스트간의 contrastive learning을 통해 feature embedding을 학습하는 인코더 사용
- 얘네는 2D image-text pair데이터가 billion-scale이고 자원 소스를 그렇게 많이 먹지 않기때문에 scratch부터 학습시킬 수 있음
- 그러나 3D data는 그들의 “희소성”과 “language의 연결부재”같은 문제점들때문에 billion-scale 데이터가 존재하지 않을뿐더러, 리소스를 너무 많이먹어서 이런 3D encoder방식으로 바로 contrastive learning을 scratch부터 시키는 것은 말 안됨
- 따라서 그 대안으로, 2D multi view이미지들로부터 3D feature를 추출하는 방법을 사용한다
- how? : pretrained 이미지 인코더로 멀티뷰에 대한 2D feeature 추출하고 이거를 2D VLM모델에게 넘겨서 3D data로 매핑시킴
- 2D 이미지 피쳐에 대응되는 3D feature가 2D VLM에게 인풋으로 들어가지는 것이기 때문에 우리는 이 2D VLM을 백본으로 삼아 활용시켜서 scratch부터 학습시킬 필요 없음
- 3D localization mechanosim 제안 : 3D spatial 정보를 더 잘 포착하게 해줌
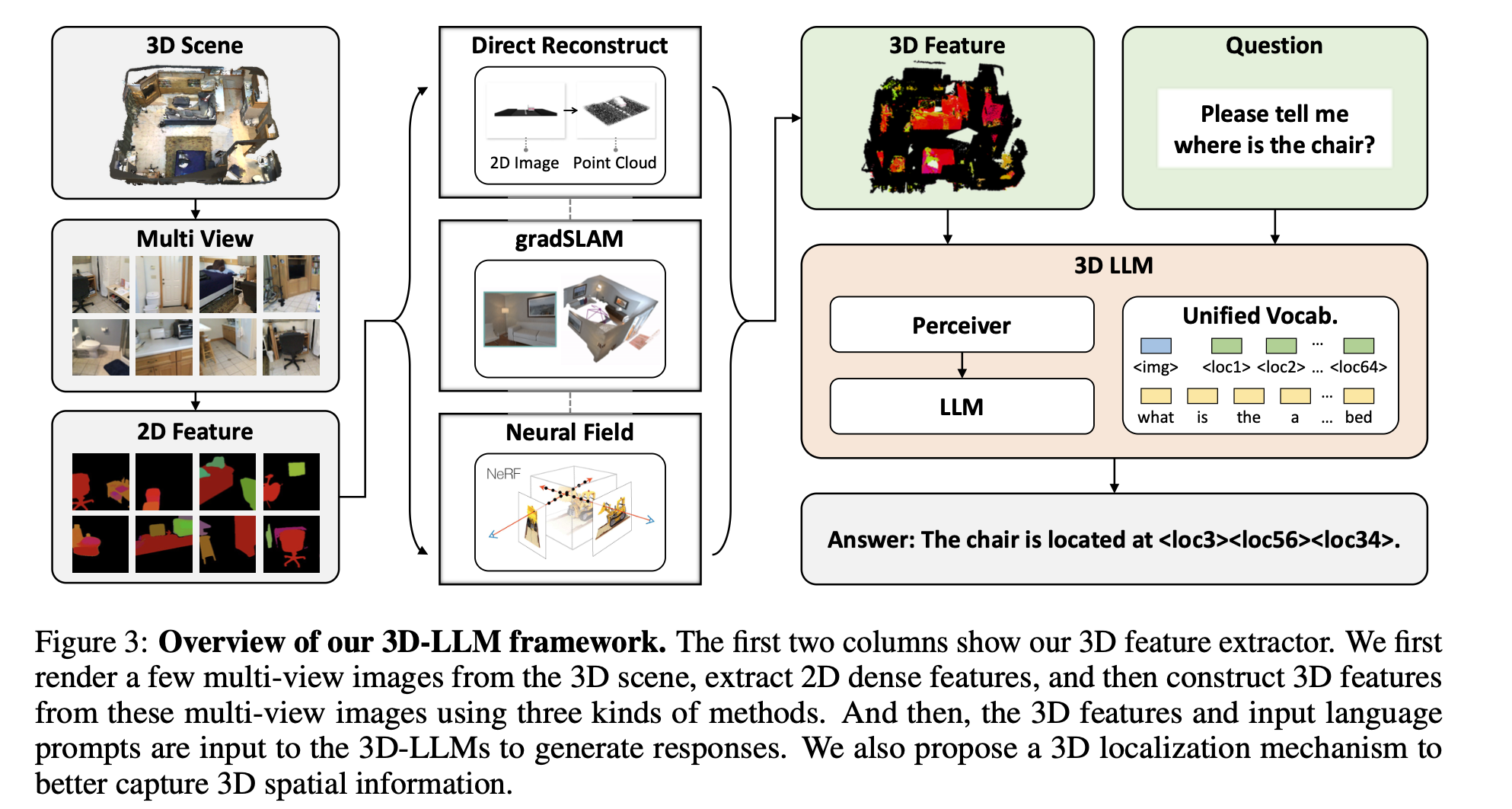
1. 3D Feature Extractor
(1) Direct Reconstruction
- 카메라 파라미터 GT값이랑 RGB-D의 2D 이미지들로부터 point cloud를 복원할 수 있음
- 정확한 카메라 intrinsic parameter주어졌을 때 적합한 방법이라 채택함
(2) Feature Fusion
- 2D feature로부터 3D feature로 매핑하는 과정 ⇒ gradSLAM 모델 사용
- 기존 dense mapping 방법들과 다르게, 추가적인 “depth”와 “color”가 함께 fusion된다 ⇒ 3D data에 적합함
(3) Neural Field
- neural voxel field 이용해서 3D field의 복셀단위로 밀도와 색깔을 포함한 feature를 저장함
- 그 이후 MSE loss를 이용해서 ray를 따라 3D feature와 pixel단위의 2D feature가 align되도록 학습함
⇒ 결과적으로 3D 장면에 대한 3D feature인 point cloud 얻음
2. 2D VLMs as backbones
- 앞선 feature extractor와 더불어 3D-LLM을 scratch부터 학습시키는 것은 빡세기 때문에 2D VLM(e.g., BLIP-2)모델을 백본으로 활용함
- 3D 특징을 2D 이미지와 같은 특징 공간(feature space) 으로 매핑할 수 있기 때문에 2D VLM을 백본(backbone)으로 활용하는 것은 합리적이라고 주장하고있음
⇒ CLIP 같은 2D 이미지 인코더는 이미 잘 학습되어 있으니, 얘네는 그대로 쓰고 파라미터는 고정(freeze)시킨다.
- 대신, 3D feature extractor를 만들어서 3D 데이터를 2D 이미지 특징 공간으로 매핑한다.
- 이렇게 하면 3D와 2D 데이터를 같은 backbone에 넣을 수 있음.
Perceiver 구조
perceiver 구조는 [DeepMind(2021)]에서 제안한 범용(multimodal) 신경망 아키텍처 => 쉽게 말하면, 입력 크기나 모달리티(이미지, 텍스트, 오디오, 3D 포인트 클라우드 등)에 상관없이 처리할 수 있는 범용 Transformer 변형
- Perceiver(또는 QFormer)는 입력 크기와 모달리티에 제약이 적음.
- 즉, 이미지처럼 고정된 크기뿐만 아니라 포인트 클라우드(3D 점 집합)처럼 크기가 가변적인 입력도 처리 가능.
- 그래서 3D 특징을 그대로 넣어도 문제없이 VLM에 활용할 수 있음.
최종 전략
- 3D feature extractor → 3D 특징 (2D와 같은 차원으로 매핑)
- frozen image encoder → 2D 특징
- 둘 다 perceiver에 입력 → pretrained 2D VLM backbone으로 학습
- 결과: 2D-기반 모델을 이용해 3D-LLM을 효과적으로 학습
3. 3D Localizaton mechanism
: 3D LLM이 단순히 “무엇(what)”만 아는 게 아니라, “어디(where)”에 있는지도 잘 이해하게 하려는 기법
(1) 3D 특징 + 위치 정보 결합
- 단순히 3D feature vector만 쓰면 “내용”은 알 수 있지만 “위치”는 놓칠 수 있음
- 그래서 (x, y, z) 좌표에 대한 sin/cos position embedding을 만들어서 feature에 추가 → 위치감각 강화
(2) 위치를 토큰으로 텍스트에 연결
- LLM은 보통 단어 단위 토큰만 이해하는데, 여기선 공간 위치도 토큰처럼 다룸
- 3D 바운딩 박스를 ⟨xmin, ymin, zmin, xmax, ymax, zmax⟩ 식으로 토큰화
- LLM의 단어 사전에 이 “위치 토큰”을 추가해서, 언어와 공간 위치를 같은 입력 공간에서 학습할 수 있도록 함
- 즉, “the red cube in the top-left” 같은 표현을 모델이 좌표 기반으로 grounding할 수 있게 됨
=> 3D LLM이 위치 정보를 잘 이해하도록, (i) 3D feature에 sin/cos 기반 좌표 임베딩을 더하고, (ii) 바운딩 박스를 위치 토큰으로 사전에 추가해 LLM과 3D 공간을 직접 연결
실험내용 생략