GS2Mesh, ECCV 2024
GS2Mesh :Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
< 선정 이유 >
- SuGaR (CVPR 2024)논문 이후로 유의미하게 3dgs의 mesh recon 태스크에서 성능이 sota달성하였다는 점,
- baseline에 SuGaR가 존재한다는 점
Abstract
- noisy한 3DGS representation으로부터 smooth한 3D mesh representation을 얻는 것 어려움
- pre-trained stereo-matching model사용해서 scene에 대한 geometry 활용함
- stereo-aligned 되어있는 image pair를 얻고, 이를 앞선 stereo matching모델에 넣어서 depth추출하여 geometry 이용함
- more smoother, more accurate mesh extraction 가능
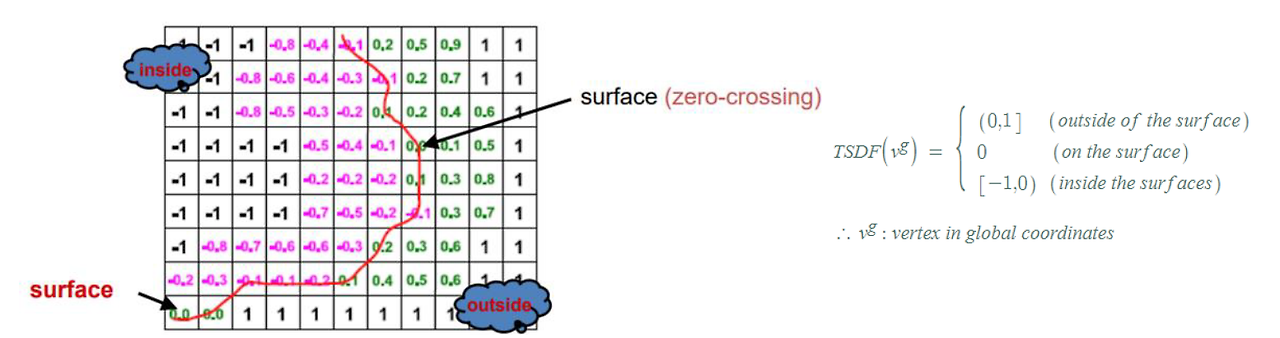
- Mesh Extraction 알고리즘 : TSDF(Truncated Signed Distance Function) 이용한 Marching cube
- Mesh Extraction 알고리즘 : TSDF(Truncated Signed Distance Function) 이용한 Marching cube
Contributions
- pre-trained stereo-matching 모델을 통해 Image pair의 geometry 활용해서 mesh reconstruction 태스크의 sota성능을 달성하였다.
- 사용한 스테레오 매칭 모델 : DLNR
- stereo calibrated image pair를 모델 input으로 사용하여 이미지 쌍에 대한 correspondence 문제를 해결 + depth 추출
- 사용한 스테레오 매칭 모델 : DLNR
- TSDF(Truncated Signed Distance Function)와 depth 정보를 활용해서 mesh recon하는 알고리즘 (marching cube기반) 사용하였다.
Introduction
- Gaussian의 explicit한 요소만으로 geometrically consistent한 surface를 추출하는 것은 어려움
- image plane(2D)에 back projected 되었을때 best matching되게끔 최적화된 가우시안이기 때문에, mesh reconstruction 에서는 오히려 가우시안 representation이 단점이 됨
stereo-aligned된 이미지 쌍에서 stereo-matching 모델(DLNR)을 사용해서 정확한 depth 측정한 후, TSDF 활용한 Depth-fusion기반 mesh extraction 알고리즘 (Marching cube) 사용하는 파이프라인
- 데이터셋 : TnT(Tanks and Temples) & DTU(작은 object mesh 데이터셋임) 에서 sota성능을 보여주었다.
Method
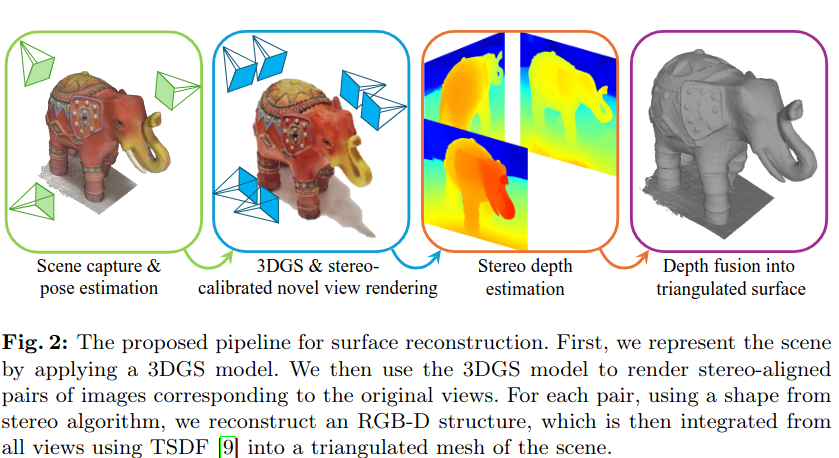
Step 1. Scene Capture & Pose Estimation
- COLMAP의 SFM(Structure From Motion)을 통해 카메라 파라미터들을 얻어내고, sparse한 3D point cloud를 재건한다.
Step 2. Stereo-aligned Image Pairs 생성
- 3DGS에서 photometric loss를 통해 최적화되어서 image plane에 back-projected된 가우시안들 기반으로 stereo-aligned(같은 베이스라인b 선상에 존재하는, 카메라 포즈(rotation, translation)은 그대로에 baseline b길이만큼만 떨어진) 한 쌍으로 만드는 과정을 수행한다.
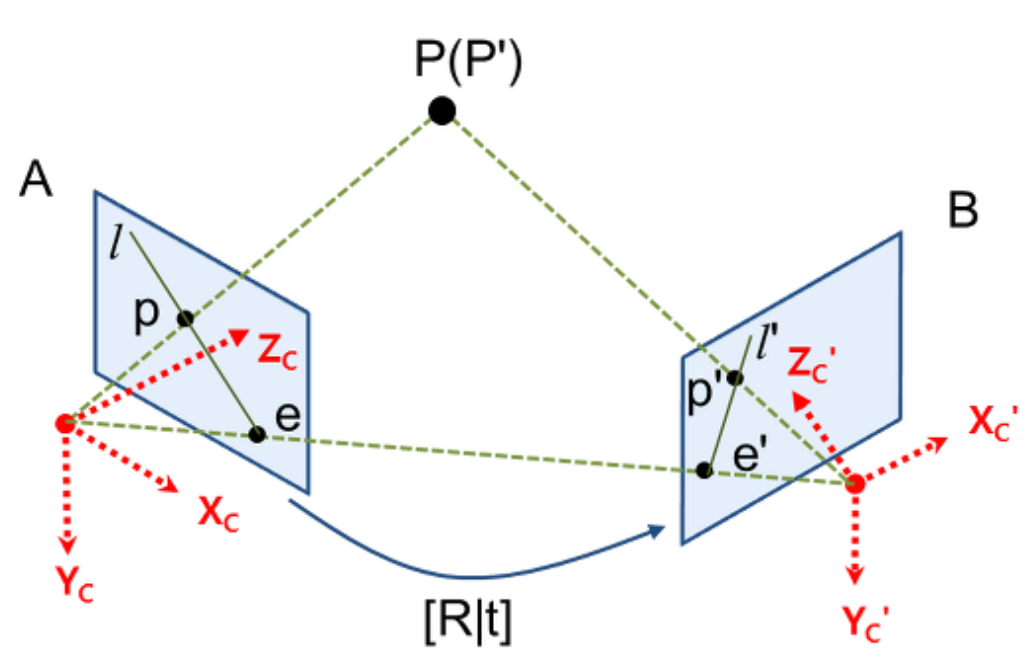
수식 Notation 설명
- $R_R$: 오른쪽 카메라의 rotation matrix - $R_L$: 왼쪽 카메라의 rotation matrix - $T_R$: 오른쪽 카메라의 translation matrix - $T_L$: 왼쪽 카메라의 translation matrixStep 3. Stereo Depth Estimation
- input : a pair of stereo-calibrated cameras
DLNR(High Frequency Stereo matching Network) 모델 이용

DLNR pipeline
- multiscale decouple LSTM 구조를 따름 + Disparity Normalization 수행하는 것이 핵심
- 논문까지 자세힌 아직 안읽어봄, 걍 stereo matching model 성능 중에 sota라고 함
이 모델 output에다가 아래의 mask 2개 정도 추가시켜 reconstruction성능 향상

- occlusion mask
- left-to-right disparity랑 right-to-left disparity 차이 이 두개 사이에서 thresholding해서 구해짐
- depth-shading
- stereo-matching error $\epsilon(Z)$
- $Z$ : ground-truth depth
- $d$ : disparity
- $f_x$ : 수평축 카메라 focal length - error가 baseline B 길이 값이 커질수록, 즉 stereo-paired image 사이의 간격이 클수록 에러가 작아지는 반면, occlusion이 심해질 수 있음
- 4B ≤ Z ≤ 20B 에 속하는 깊이만을 고려함
- occlusion mask
Step 4. Depth Fusion into Triangulated Surface (mesh)
- 추출된 depth 정보들을 TSDF(Truncated Signed Distance Function) 기반 mesh reconstrucction 방법에 통합시킨다
TSDF Cube Model이란?
: 깊이 영상 으로부터 3차원 공간 표면을 효과적으로 표현하기 위해,
전체 공간을 일정한 크기의 정육면체 복셀(voxel)들로 구성된 커다란 하나의 큐브(cube)로 표현하고, 각 복셀에는 물체 표면과의 거리를 나타내는 TSDF값과 그 값의 신뢰도를 나타 내는 가중치(weight)를 함께 저장하는 방식
etc에 TSDF 개념 간단하게 추가
- Marching cube : mesh 만들어주는 알고리즘
- sdf나 tsdf같은 함수 활용되며, surface representation 방식 기반으로 mesh 뽑아냄
- sdf나 tsdf같은 함수 활용되며, surface representation 방식 기반으로 mesh 뽑아냄
Experiment
- ground truth point cloud랑 reconstructed point cloud간의 Chamfer Distance(CD)계산을 통해 evaluation
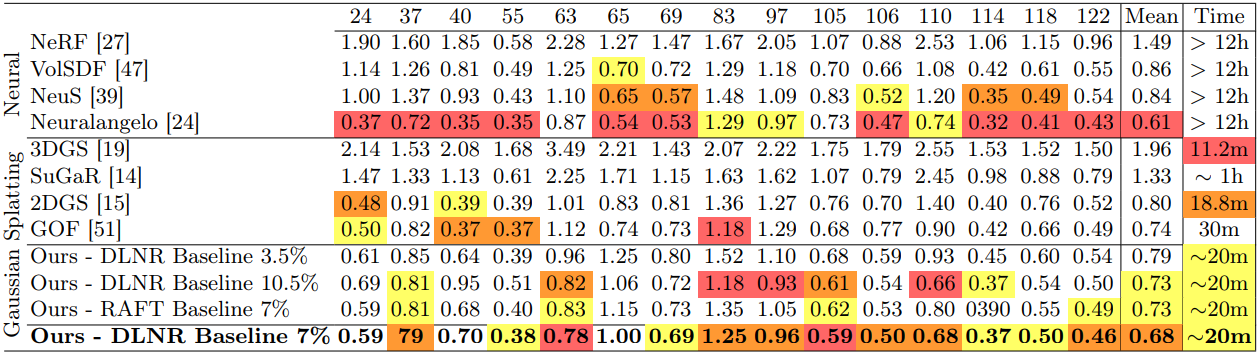
- Baseline : SuGaR(CVPR 2024), BakedSDF, Neuralangelo, VolSDF, NeuS, MVSformer,
- 데이터별로 실험 진행 얘기
- 평가 지표 : Chamfer-Distance(CD): 두 point cloud 집합간의 거리 측정, F1, Accuracy

Limitation

- 오른쪽 스테레오 매칭 모델은 투명한 표면에서 어려움을 겪는다.
- (왼쪽) 원래 학습 이미지에서 충분히 다루어지지 않은 영역에서 floater를 생성한다.
- TSDF 퓨전은 큰 장면(넓은 baseline B)에 맞게 확장되지 않는다.
etc., (Preliminaries)
기초 개념
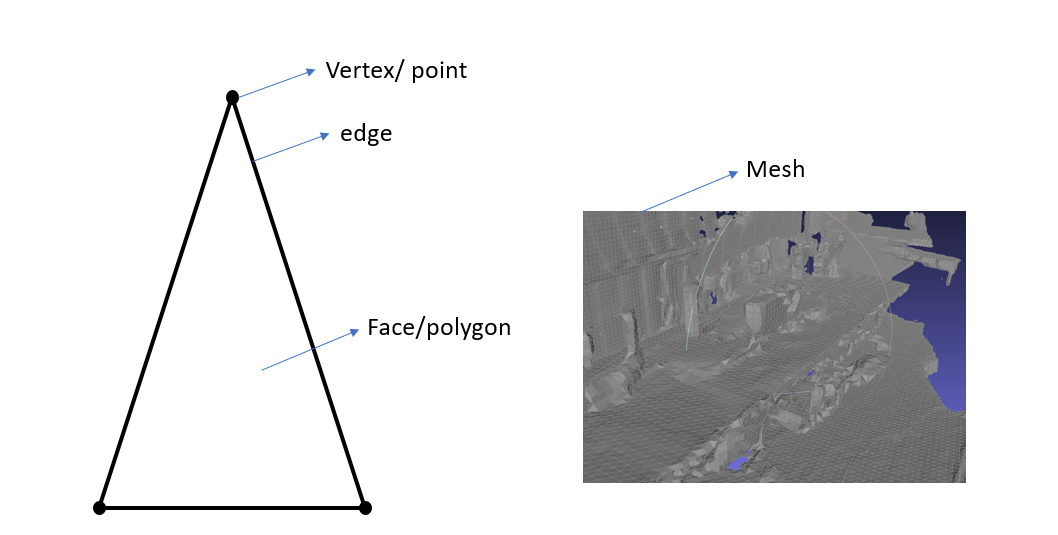
Mesh란?
: 3D 공간상에 존재하는 점들(Vertex/ Point) 과 그 점 3 개의 집합인 면(Polygon/face)들로 이루어진 3D 공간 표현방법
Voxel이란?
:이미지의 pixel 처럼 3D 공간을 표현하기 위해서 3D공간을 작은 단위 공간으로 쪼갠 것 –> 3차원 공간을 grid로 쪼갰다고 보면 편함
TSDF (Truncated Signed Distance Function)
- 3D scene reconstruction의 목적은 Surface 를 찾아 recon 하는 것인데 이때 surface 를 표현하는 함수를 SDF(Signed Distance Function) 라고 함
Voxel 형태로 단위공간을 나누어 surface 라고 판단되는 곳은 0, Surface 안쪽은 음수 , Surface 바깥쪽은 양수로 표현하는 방식
Marching Cube (SIGGRAPH 1987)
- 과정 다 생략하고 한 줄 요약 : 3D point cloud로부터 Mesh 생성 알고리즘
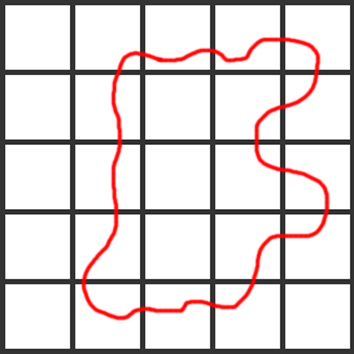
2차원 image plane에서 물체가 빨간색 선처럼 생겼다고 생각해보자, (3차원에서는 voxel임)
이것을 2차원 도트로 표현하면 아래와 같음
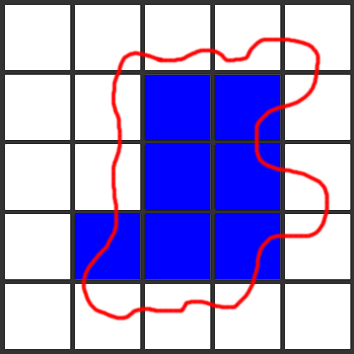
⇒ 원형의 물체랑 너무 달라짐, 해상도 차이 발생, 모양 이상해지는 결과
따라서, 마칭 큐브 알고리즘으로 surface reconstruction을 진행한다. (…TLDR)
=> 마칭 큐브 알고리즘 다음 게시물에 정리 이어서,,
느낀점
- Marching Cube 알고리즘부터 완벽하게 이해를 해보자
- 항상 간단한 정리글로만 읽고 넘어가니까 그냥 point cloud넣고 mesh뽑아주는 그래픽스 알고리즘이다정도라고만 알고 넘어가서 모호하다, 알짜배기를 모르는 느낌
- SuGaR에서는 Poisson reconstruction기반의 mesh recon알고리즘을 썼다고 되어있었는데, 이게 나는 마칭 큐브랑 완전 다른 건 줄 알았는데 또 읽다보니 포아송재건도 마칭큐브기반이라는 소리도 있고 출처가 정확하지 않으니까 혼동된다, 그래서 Poisson Reconstruction 논문도 읽어야겠다
- eccv논문인데 생각보다 노벨티가 뭐가 없다
- 그냥 stereo-matching 모델 써서 depth추출하고 이거 기반으로 point cloud를 더 정확하고 밀도있게 뽑아내고 그 후로는 그냥 알고리즘 사용해서 메쉬추출한건데,, 성능이 좋았다는게 신기하다.
- 대신 단점이 명확하다, stereo 기법이다보니 위의 triangulation사진을 보다시피 베이스라인 길이에 한정된 씬만 사용될 것이므로 넓은 즉 큰 반경의 scene에 대한 mesh recon은 잘 안될 것이다 (실제로 사용한 데이터셋들도 다 작은 object based 벤치마크들이다)
- 3DGS도 그렇고, mesh recon도 그렇고 고질적인 문제가 투명한 transparent한 물체가 잘 복원이 어렵다는 점인데, 이부분의 개선은 왜 안되고 있는지 렌더링 측면에서 공부를 좀 더 해봐야겠다.