PERSONA, ICCV 2025
PERSONA, ICCV 2025
기존 선행 연구들 문제
(1) 3D 기반:
- 3DGS + SMPL-X같은 뉴럴렌더링 활용하는방법 ⇒ 주로 강체(rigid) 변형만을 지원하는 3D 파라메트릭 모델을 활용하기 떄문에, 변형가능한(non-rigid)한 옷의 주름을 포착하기 위해서는 다양한 Pose정보가 포함된 대규모 데이터셋으로 학습이 필요함
(2) 2D 기반:
- diffusion활용
- gemotry정보 잡는거 취약하고 multi-view에 의해 복원 inconsistency함
Persona’s Contributions
- 앞선 3D neural rendering기반 메소드랑 2D diffusion기반 메소드의 장점만 모아서
- 단일 이미지 한 장으로 pose-driven deformation(변형) 잘 포착하는 3D 아바타 복원하는 메소드
(1) Balanced sampling
- 아바타 최적화하는동안 input image oversampling하는거 + pose에 의존적인 geometry와 그림자같은 내재된 artifact 예방
(2) geometry-weighted optimization
- sharp rendering + texture 유지하기 위해 제안
Overview
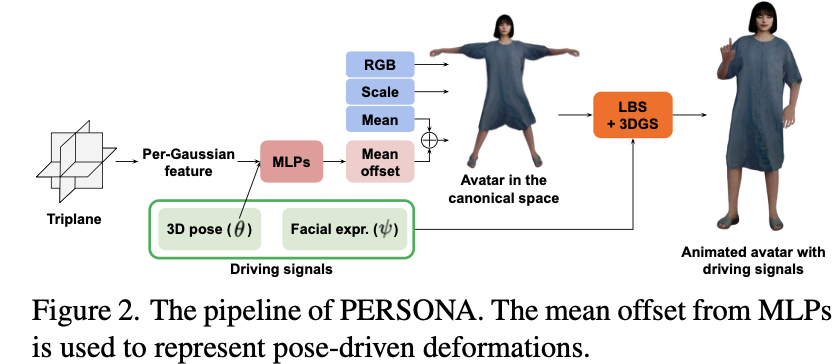
- SMPL-X 모델(whole-body animation)이랑 3DGS(texture복원 및 geometry 이용)
- 3DGS(Mip-splatting 이용)기법에서 mean-offset 소개 ⇒ pose-driven(non-rigid) deformation의 성능을 잘되게 함
MLP의 input으로 가우시안의 triplane feature를 넣음
: triplane feature란 = 세 개의 직교하는 2D 평면을 의미함
⇒ 3D gaussian splat 포인트가 단순히 색, 크기같은 물리적인 속성만 특성으로 갖고있는것이 아니라, 세개의 2D 평면(XY, YZ, XZ)에서 뽑은 feature embedding으로 보강된 표현을 뜻함 ⇒ 메모리 효율성이 좋고 가우시안의 삼평면 기반 보강된 neural representation이 되면서 “텍스처”, “세밀한 표면”속성같은 정보를 포함할 수 있게 됨
- SMPL-X의 shape 파라미터 가져와서 “geometric identity” 보존 ⇒ 3D pose랑 facial expression 둘다 SMPL-X에서 가져옴 ⇒ MLP에 같이 넣음
= 그 이후, canonical space에서 가장먼저 아바타 constructed되고
그 다음에 LBS(Linear-blend skinning)로 아바타 자연스럽게 animated된 이후, 최종 Mip-Splatting으로 3D 공간에서 rendering하는 흐름
Method
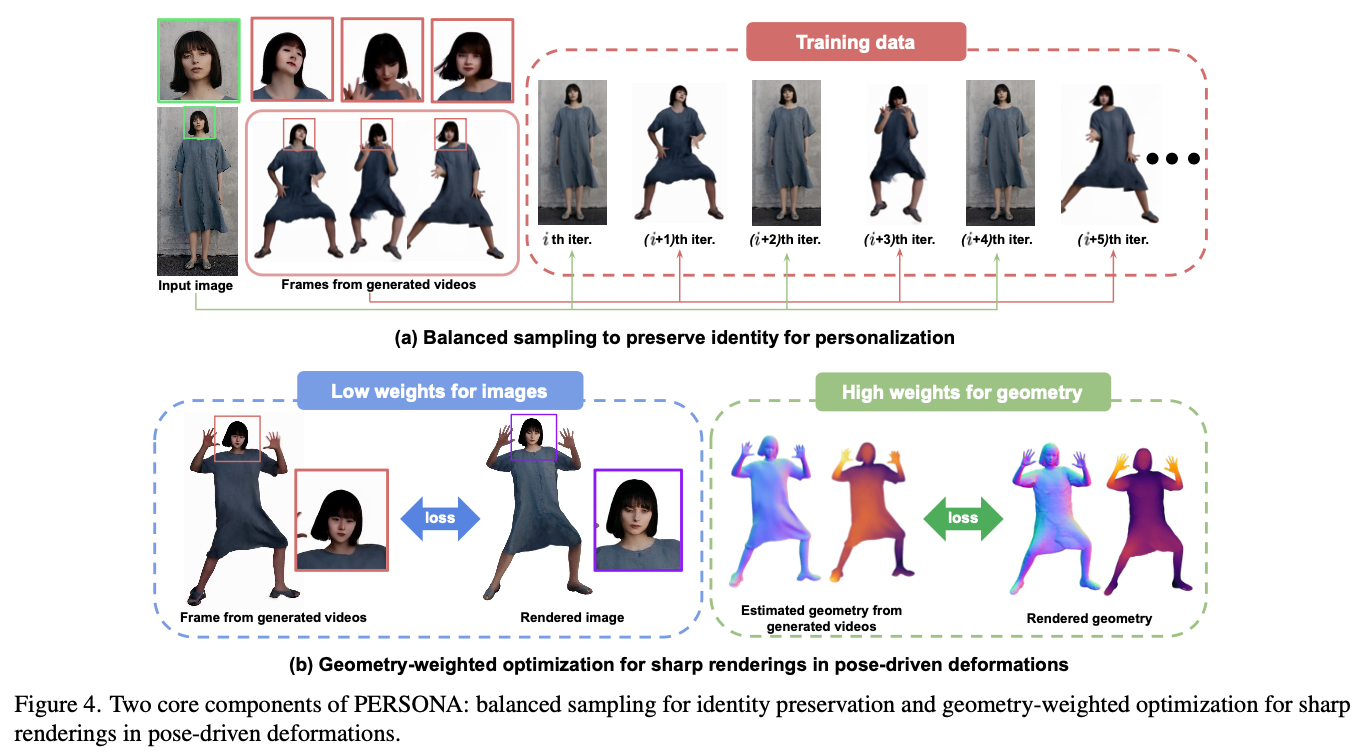
Pose-driven(non-rigid) deformation
(1) Balanced Sampling
- 디퓨전 기반 메소드들은 “주어의 identity(특히 얼굴표정)”를 잃는 것이 태반임
- Baked-in-Artifacts : 그림자 지는 곳, 옷 쭈글거리는 부분 ⇒ canonical 공간에서 렌더링된 아바타에서도 보이는 문제임
- 해결 방법 :
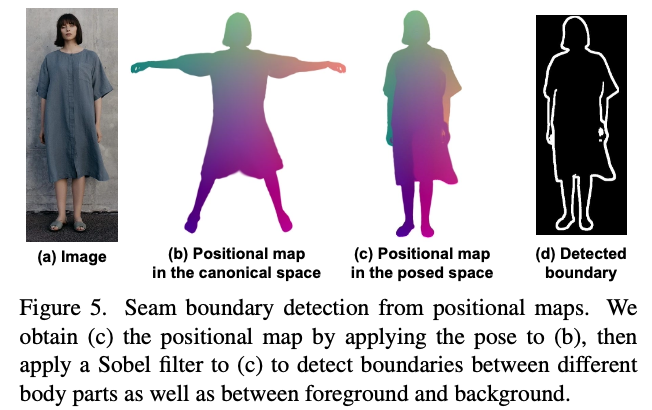
- positional map에서 sobel filter(edge detection해주는 2D image process filter)먹여가지고 seam boundary(옷 경계선) 따서 이 전경과 배경을 분리함으로써 신체부위간의 내부 경계도 탐지할 수 있음
- albedo 이미지 활용 : 음영지는곳이 많은 이미지 즉, 그림자 지는 영역 많아지면 artifact심해지니까 이를 최소한으로 포함하는 , 특히 “texture”표현할 때 그림자 artifact를 최소화하는데 도움되는 이미지인 알비도 이미지를 추가적인 supervison 정보로 사용
(2) Geometry-weighted optimization for Sharp rendering
- low-loss weight on low images & high loss weights on geometry
- Geometry : binary mask, depth, normal, part segmentation
- texture 퀄리티에서 불안정함 일반 렌더링(rigid)한 부분에서는 ㄱㅊ음
- binary mask : color value이용
- depth map : 렌더링된 가우시안의 depth는 각 가우시안의 “색깔 속성”으로 취급됨
- normal maps : 렌더링된 가우시안 각각의 normal vector이용해서 계산됨 + ExAvatar의 hybrid representation이용
- part segmentation : RGB이미지로 표현되고 각 색깔은 Sapiens palette(모델 이름)에 기반되어 몸 부위마다 세그멘트되는거 활용
- texture 퀄리티에서 불안정함 일반 렌더링(rigid)한 부분에서는 ㄱㅊ음
(3) Mean offsets
- sharp rendering 유지하기 위해서 제안
- isotropic(등방성⇒ 모든 방향에서 분산(scale)이 동일한 것) 가우시안에다가 mean-offset만 적용
- 등방성 가우시안이 되기 때문에 가우시안 각각의 shape이 고정되어서 이게 변형되더라도 blurry해지지 않게됨
- position-only 변형에 해당됨
- 반면, scale offset은 가우시안이 단순히 커지거나 작아지면서 이동하지 않기 때문에 결과가 흐릿하게 렌더링될 수 있는 문제있음 + RGB 오프셋은 생성된 프레임으로부터 신뢰할 수 없는 색상을 복사할 위험
Optimization
- 최적화한 파라미터들 : 3D Gaussian features(means, scales, RGB colors) + triplane, MLP weights, per-frame SMPL-X parameters
- 고전적인 image reconsgtruction loss들 ($L_1$,SSIM, LPIPS)과 geoemtry regularizer(라플라시안 정규화같은)도 같이 이용해서 학습시킴
- (2) Geometry-weighted optimization: 최종 rendered된 output과 target geometry map(e.g., normal map, depth map, ..)사이의 $L_1$ loss도 최소화되게 학습
- geoemtric plausibility를 위해, “손”영역에서는 3DGS와 SMPL-X hand model로 렌더링된 meshes들 사이의 각각 $L_1$ loss를 사용하여 최적화함
Experiments
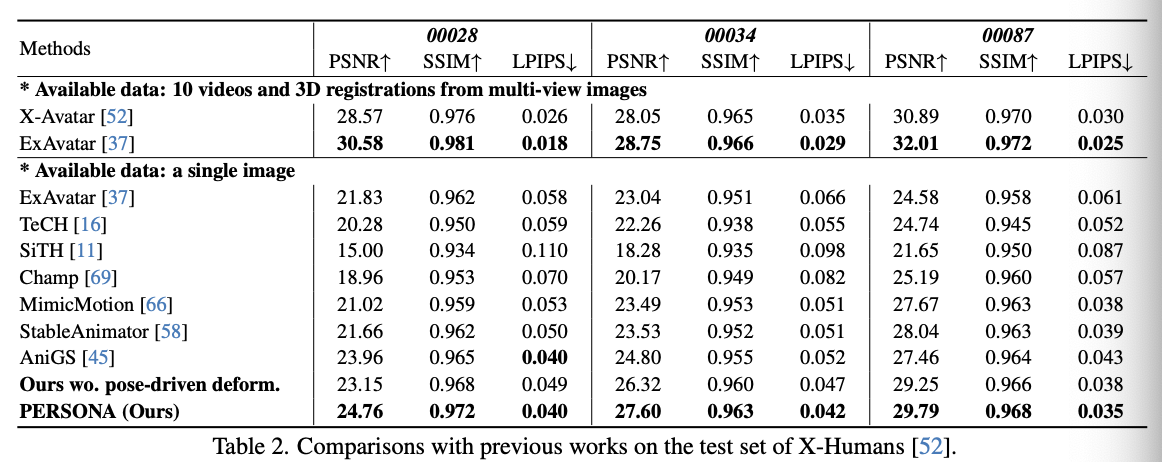
- evaluation metrics: PSNR, SSIM, LPIPS
- evluation(test) datas: X-Humans, NeuMan
- comparison methods: NeuMan, ExAvator, LHM, AniGS, Champ, GaussianAvatar, ….
Results
- qualitative & quantiatitve

느낀점
- 이미지 피킹한 페이지가 많아서 본문 설명 글이 별로 없었다
- 메소드자체는 엄청 어려워보이진 않는데 SMPL-X랑 mip-splatting 코드 합치고 짜는게 어려웠을 것 같다
- 핵심 컨트리뷰션에서 mean-offset을 위해서 mlp인풋으로 주는 triplane gaussian관련 처음 나온 논문 : Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers » 이 논문도 같이 읽어봐야겠다
- 개인적으로 전체 overview pipeline을 너무 대충 그려놓으셔서 아쉬웠다 일부러 quantiative 결과들 많이 보여줘야돼서 분량상 그런것같긴한데
This post is licensed under CC BY 4.0 by the author.